Learn
1 / 9
2 / 9
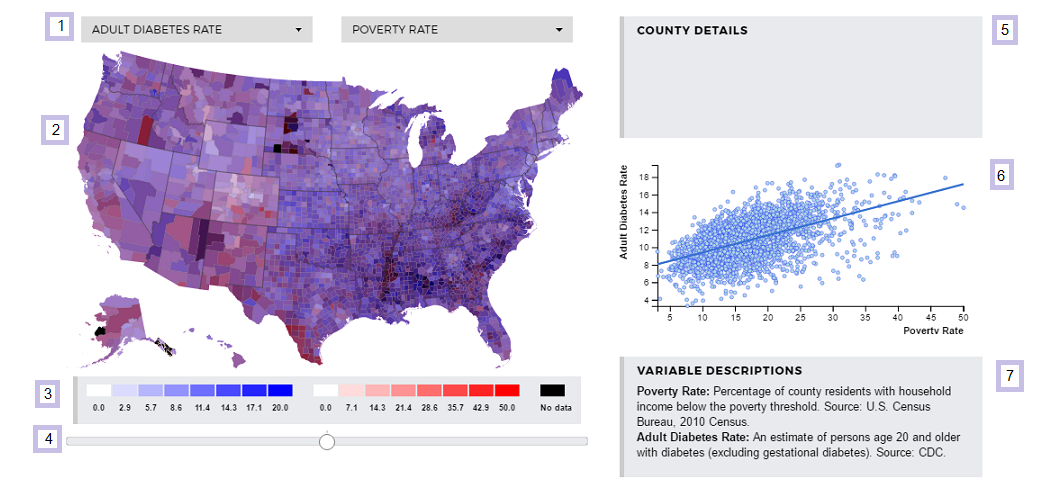
Let's start our exploration by familiarizing ourselves with the layout. At element 1,
there are two drop down bars with which you can select variables to compare. Two choropleth maps
are layered in element 2: the left variable in blue, the right variable in red. A legend
describing the color values appears below the map in element 3. Element 4 is a slider bar,
allowing you to slide to either side to view the distribution of that variable alone.
By default the map is overlaid so you can find patterns. Many purple regions implies the
variables are positively correlated with each other, patches of red and blue implies
negative correlation, and patches of all three implies no correlation.
When you hover over a county, the county name, state, diabetes and obesity rates, and
the values of the variables you have selected will appear in element 5.
Element 6 contains a scatterplot of the distribution of counties for the selected variables
and a linear regression line, and element 7 contains the definitions of the variables selected.
3 / 9
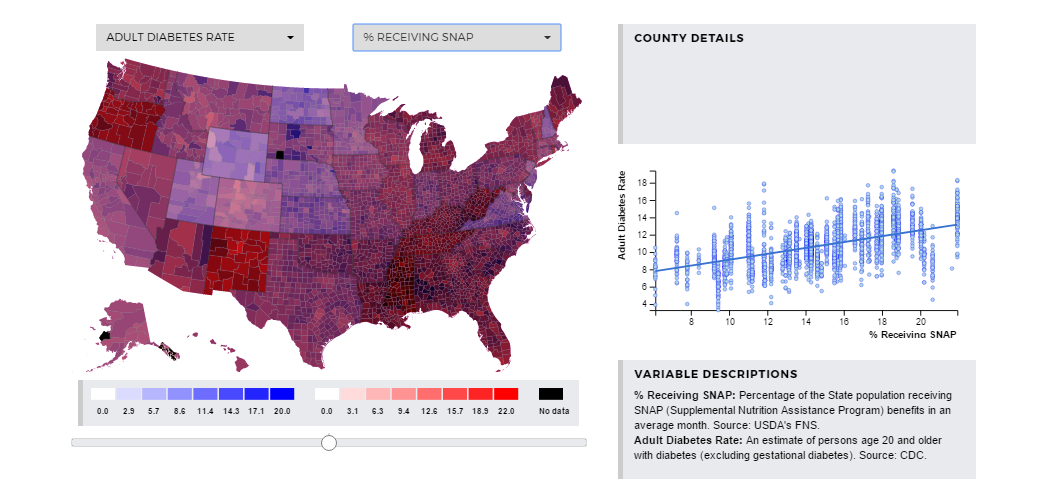
Here, we can explore the percentage of households receiving SNAP benefits and its
relationship to the percentage of adults with diabetes. The percentage of adults
with diabetes increases as the percentage of the population receiving SNAP benefits
increases with R-Squared=0.0125. This means that about 1.3% of variation in adult
diabetes in a county can be explained by variation in the percentage of households
receiving SNAP benefits. This could mean many things: that households receiving SNAP
benefits are more likely to eat less nutritious food due to pricing, or possibly the
two have nothing to do with each other and there is something else causing variation
in both SNAP benefits and adult diabetes rates.
4 / 9
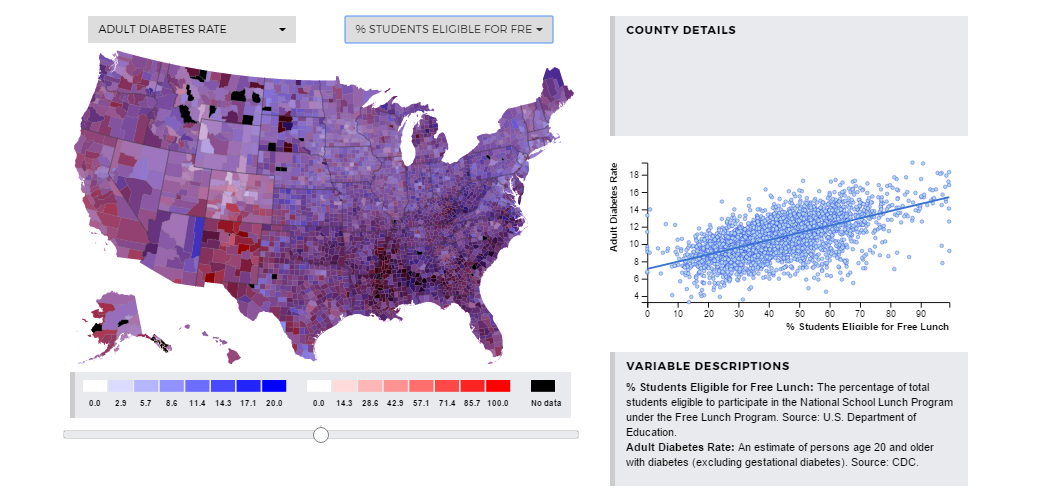
Here, we can explore the percentage of students eligible for free lunch benefits
and its relationship to the percentage of adults with diabetes. The percentage of
adults with diabetes increases as the percentage of students eligible for free lunch
increases (R-Squared 0.0229). This means that about 2.3% of variation in adulthood
diabetes can be explained by variation in the percentage of students eligible for
free lunch. Perhaps families with lower income in which the children qualify for
free lunch cannot afford food with enough nutritional variety. This would cause an
increase in diabetes among the adults. Again, there is no way to determine what causes
this relationship, but it exists and therefore is important to consider.
5 / 9
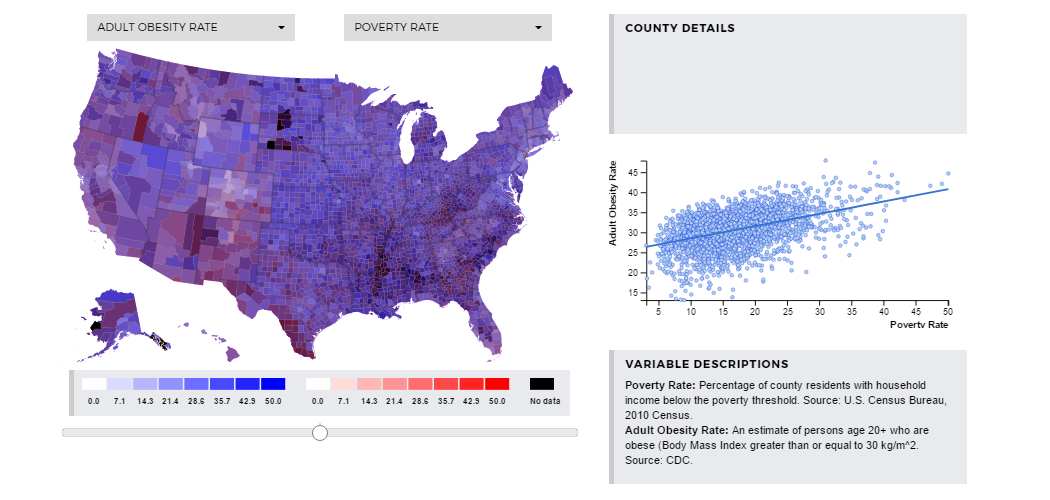
Here, we can explore the relationship between the poverty rate the obesity rate in a county.
The adult obesity rate increases with the poverty rate with R-Squared=0.0122. From this we
learn 1.2% of variation in adult obesity can be explained by variation in the poverty rate.
It is possible that there is another factor common to these areas that causes these rates to
have such a strong relationship? Or do people living in poverty simply have less access to
nutritious food, and thus their diet causes obesity?
6 / 9
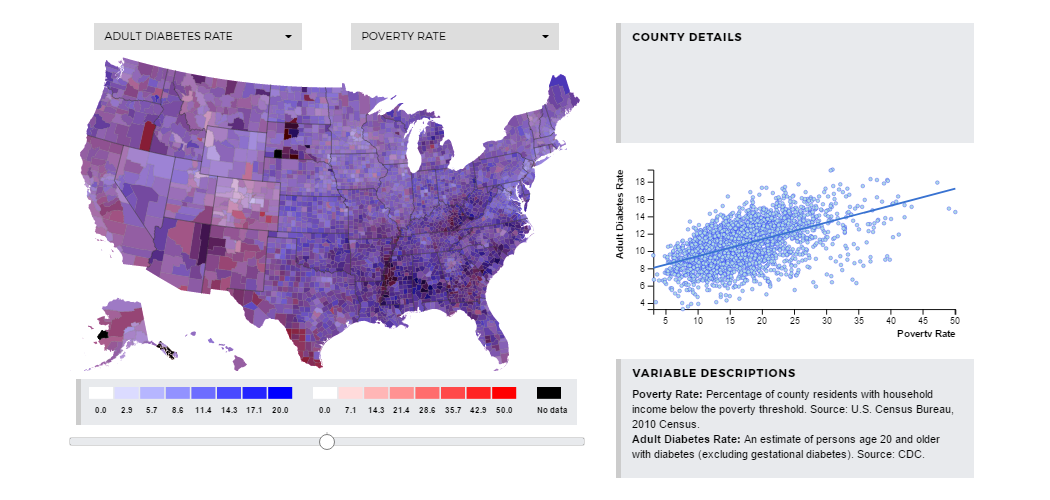
Here, we can explore the relationship between the poverty rate the diabetes rate in
a county. The adult diabetes rate increases with the poverty rate with R-Squared=0.0169
From this we learn 1.7% of variation in adult diabetes can be explained by variation
in the poverty rate. It is possible that there is another factor common to these areas
that causes these rates to have such a strong relationship? Or do people living in
poverty simply have less access to nutritious food, and thus their diet contributes
to the development of diabetes?
7 / 9
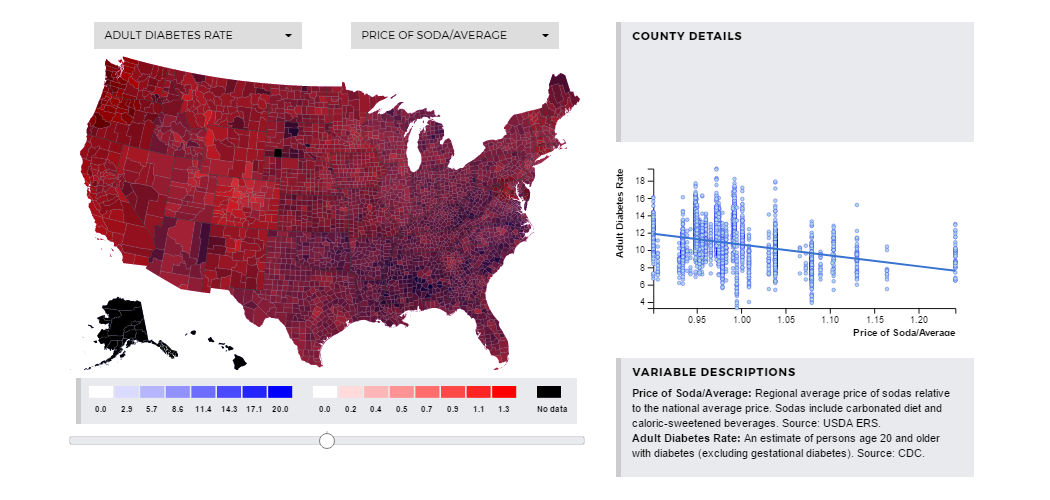
Here, we can explore the relationship between the percentage of adults with diabetes
and the price of soda in each county. The diabetes rate decreases as soda price increases
with P-value < 0.0001 and R-Squared about 0.0094. This means that about 1% of change in
the diabetes rate in each county can be attributed to change in the price of soda. A
possible explanation for this relationship is that higher soda prices discourage people
from consuming soda, decreasing people’s sugar consumption and thus potentially decreasing
the diabetes rate. However, there are many possibilities.
8 / 9
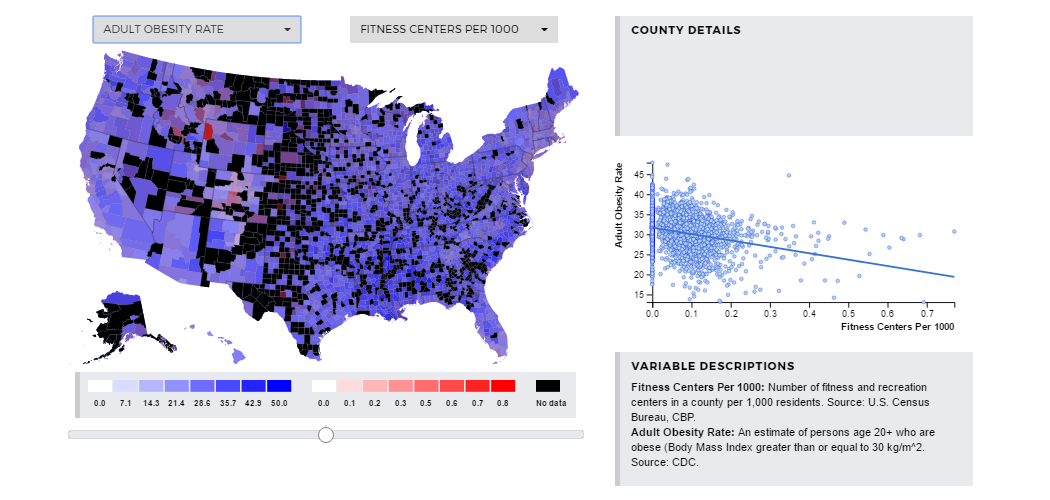
Here we explore the relationship between the adult obesity rate and the number of recreation and fitness
facilities available. An increased number of recreation and fitness facilities correlates with decrease
obesity rates with R-Squared= 0.0332. This means that 3.2% of variation in obesity rates can be explained
by variation in the availability of fitness facilities. It is possible that counties with many recreation
facilities may also have other attributes that lead to lower obesity rates. Or, it’s possible that higher
availability of fitness centers means more people have access to exercise and thus the obesity rate is lower.
Counties with more fitness facilities likely have higher demand for fitness facilities. This demand could
either be created by a wealthier population, or just a population more aware of the health benefits of
exercise. It is also important to notice the lack of data for many counties. Regardless, this relationship
could be important to consider when policy is discussed.
9 / 9
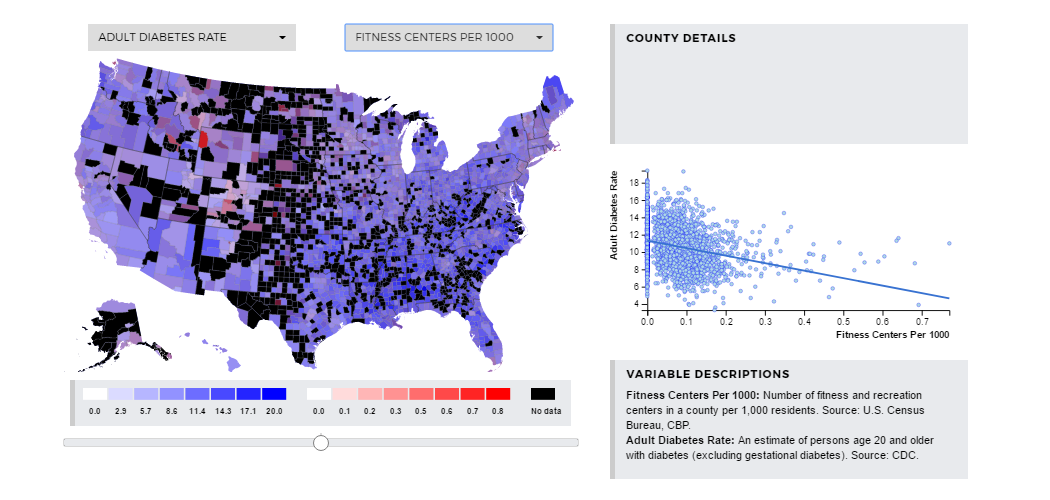
Here we explore the relationship between the diabetes rate and the number of recreation and
fitness facilities available. An increased number of recreation and fitness facilities
correlates with decrease diabetes rates. Adult diabetes decreases as this number increases
with R-Squared= 0.0761. This means that 7.6% of variation in diabetes rates can be explained
by variation in the availability of fitness facilities. It is possible that counties with many
recreation facilities may also have other attributes that lead to lower diabetes rates. Or, it’s
possible that higher availability of fitness centers means more people exercise and thus the
diabetes rate is lower. It is a very important trend to notice due to its strength. It is also
important to notice the lack of data for many counties. This relationship could be important to
consider when policy is discussed.